Floating point numbers and unsigned bytes are both used in graphics. Generally 0..1 for float and obviously 0..255 for unsigned byte.
It's nice when we can stick to one or the other, but sometimes that doesn't work and we have to convert between them.
There are details. Once again there are always details. And I've seen people get them wrong. Often I've seen this implemented with truncation rather than rounding - which makes me sad. I've also seen a direct cast to byte, without limiting to zero and 255 - which makes me sad.
Pretty much all of the float SSE instructions are affected by the rounding mode. Pretty much nobody changes these bits without changing them back when they're done. Setting the bits is a little expensive - pretty much everything has to stop in order to do this. But amortized over a function call it's not bad.
__forceinline unsigned char Saturate_Int32_To_UnsignedInt8(const int x)
{
return std::min(255, std::max(0, x));
}
__forceinline unsigned char Saturate_float_To_UnsignedInt8(const float x)
{
// since we can't set the rounding mode for simple ANSI, we'll do the normal thing and add 0.5f and truncate towards zero.
int ic = (int)((255 * x)+0.5f);
return Saturate_Int32_To_UnsignedInt8(ic);
}
void convert_floats_to_bytes(const float *pF, unsigned char *pUC, const size_t cF)
{
// setting the rounding mode is generally unnecessary... But to be safe....
const unsigned int uiStoredRoundingMode = _MM_GET_ROUNDING_MODE();
_MM_SET_ROUNDING_MODE(_MM_ROUND_NEAREST);
size_t cFRemaining = cF;
while (cFRemaining & 3)
{
cFRemaining--;
pUC[cFRemaining] = Saturate_float_To_UnsignedInt8(pF[cFRemaining]);
}
if (cFRemaining > 0)
{
__m128 mScale = _mm_set1_ps(255);
if (cFRemaining & 4)
{
cFRemaining -= 4;
__m128 mF = _mm_loadu_ps(&pF[cFRemaining]);
__m128 mFScaled = _mm_mul_ps(mF, mScale);
__m128i mIScaled_epi32 = _mm_cvtps_epi32(mFScaled);
__m128i mIScaled_epi16 = _mm_packs_epi32(mIScaled_epi32, _mm_setzero_si128());
__m128i mIScaled_epu8 = _mm_packus_epi16(mIScaled_epi16, _mm_setzero_si128());
int iConvertedOut;
iConvertedOut = _mm_cvtsi128_si32(mIScaled_epu8);
*((int *)&pUC[cFRemaining]) = iConvertedOut;
}
while (cFRemaining > 0)
{
cFRemaining -= 4;
__m128 mFHi = _mm_loadu_ps(&pF[cFRemaining]);
cFRemaining -= 4;
__m128 mFLo = _mm_loadu_ps(&pF[cFRemaining]);
__m128 mFScaledHi = _mm_mul_ps(mFHi, mScale);
__m128 mFScaledLo = _mm_mul_ps(mFLo, mScale);
__m128i mIScaledHi_epi32 = _mm_cvtps_epi32(mFScaledHi);
__m128i mIScaledLo_epi32 = _mm_cvtps_epi32(mFScaledLo);
__m128i mIScaled_epi16 = _mm_packs_epi32(mIScaledLo_epi32, mIScaledHi_epi32);
__m128i mIScaled_epu8 = _mm_packus_epi16(mIScaled_epi16, _mm_setzero_si128());
__int64 iConvertedOut;
#if defined (_M_X64)
iConvertedOut = _mm_cvtsi128_si64(mIScaled_epu8);
#else
iConvertedOut = mIScaled_epu8.m128i_i64[0];
#endif
*((__int64 *)&pUC[cFRemaining]) = iConvertedOut;
}
}
_MM_SET_ROUNDING_MODE(uiStoredRoundingMode);
}
This doesn't make me sad.
Thursday, March 23, 2017
Tuesday, March 21, 2017
a bitonic sorting network for 16 signed short in SSE2
We saw a sorting network for 8 float numbers. These values fit nicely into two 128bit registers.
Twice as many signed shorts can be fit into the same space. And SSE2 has intrinsics for maximum and minimum for 8 signed short numbers at a time using _mm_min_epi16 and _mm_max_epi16.
While the bitonic sorting network for 16 values requires 10 min/max pairs rather than the 9 required in the network shown in Knuth, the shuffles are much easier for the plain vanilla bitonic sorting network.
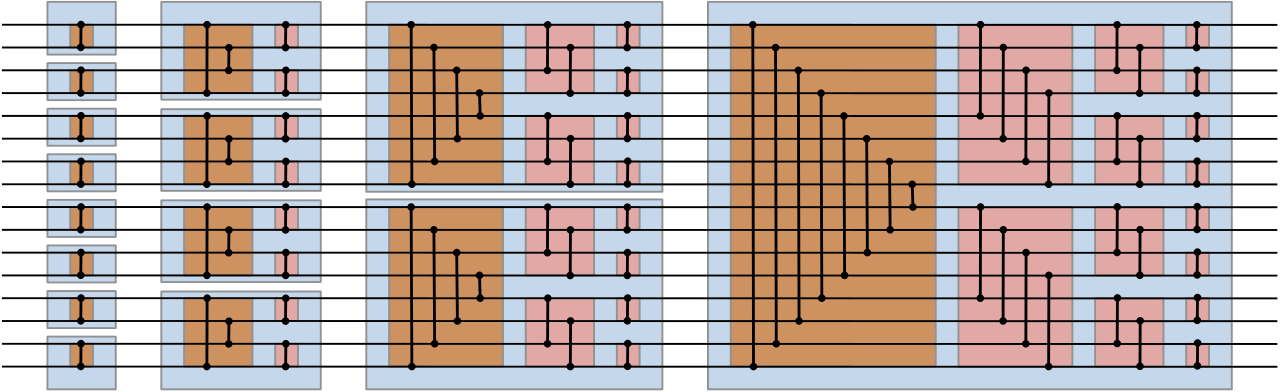
A lot of shuffling has to happen to make this all work. The unpack operations will happen in pairs:
void unpack_epi16_ab(const __m128i &a, const __m128i &b, __m128i &aOut, __m128i &bOut)
{
__m128i aa = _mm_unpacklo_epi16(a, b);
__m128i bb = _mm_unpackhi_epi16(a, b);
aOut = aa;
bOut = bb;
}
void unpack_epi32_ab(const __m128i &a, const __m128i &b, __m128i &aOut, __m128i &bOut)
{
__m128i aa = _mm_unpacklo_epi32(a, b);
__m128i bb = _mm_unpackhi_epi32(a, b);
aOut = aa;
bOut = bb;
}
void unpack_epi64_ab(const __m128i &a, const __m128i &b, __m128i &aOut, __m128i &bOut)
{
__m128i aa = _mm_unpacklo_epi64(a, b);
__m128i bb = _mm_unpackhi_epi64(a, b);
aOut = aa;
bOut = bb;
}
Note that it is safe to call all of these with the same variables used as input and output.
void BitonicSortingNetwork_epi16_SSE2(const __m128i &a, const __m128i &b, __m128i &aOut, __m128i &bOut)
{
__m128i a1 = a;
__m128i b1 = b;
__m128i a1Min = _mm_min_epi16(a1, b1);
__m128i b1Max = _mm_max_epi16(a1, b1);
__m128i a2 = a1Min;
__m128i b2 = _mm_shufflelo_epi16(b1Max, _MM_SHUFFLE(2, 3, 0, 1));
b2 = _mm_shufflehi_epi16(b2, _MM_SHUFFLE(2, 3, 0, 1));
__m128i a2Min = _mm_min_epi16(a2, b2);
__m128i b2Max = _mm_max_epi16(a2, b2);
__m128i a3, b3;
unpack_epi16_ab(a2Min, b2Max, a3, b3);
unpack_epi16_ab(a3, b3, a3, b3);
unpack_epi16_ab(a3, b3, a3, b3);
__m128i a3Min = _mm_min_epi16(a3, b3);
__m128i b3Max = _mm_max_epi16(a3, b3);
__m128i a4, b4;
unpack_epi32_ab(a3Min, b3Max, a4, b4);
a4 = _mm_shufflelo_epi16(a4, _MM_SHUFFLE(0, 1, 2, 3));
b4 = _mm_shufflehi_epi16(b4, _MM_SHUFFLE(0, 1, 2, 3));
__m128i a4Min = _mm_min_epi16(a4, b4);
__m128i b4Max = _mm_max_epi16(a4, b4);
__m128i a5, b5;
unpack_epi16_ab(a4Min, b4Max, a5, b5);
unpack_epi64_ab(a5, b5, a5, b5);
a5 = _mm_shuffle_epi32(a5, _MM_SHUFFLE(2, 3, 0, 1));
__m128i a5Min = _mm_min_epi16(a5, b5);
__m128i b5Max = _mm_max_epi16(a5, b5);
__m128i a6, b6;
unpack_epi16_ab(a5Min, b5Max, a6, b6);
unpack_epi16_ab(a6, b6, a6, b6);
__m128i a6Min = _mm_min_epi16(a6, b6);
__m128i b6Max = _mm_max_epi16(a6, b6);
__m128i a7, b7;
b7 = _mm_shuffle_epi32(b6Max, _MM_SHUFFLE(1, 0, 3, 2));
b7 = _mm_shufflehi_epi16(b7, _MM_SHUFFLE(0, 1, 2, 3));
a7 = _mm_shufflelo_epi16(a6Min, _MM_SHUFFLE(0, 1, 2, 3));
__m128i a7Min = _mm_min_epi16(a7, b7);
__m128i b7Max = _mm_max_epi16(a7, b7);
__m128i a8, b8;
unpack_epi16_ab(a7Min, b7Max, b8, a8);
a8 = _mm_shuffle_epi32(a8, _MM_SHUFFLE(0, 1, 2, 3));
__m128i a8Min = _mm_min_epi16(a8, b8);
__m128i b8Max = _mm_max_epi16(a8, b8);
__m128i a9, b9;
unpack_epi16_ab(a8Min, b8Max, a9, b9);
__m128i a9Min = _mm_min_epi16(a9, b9);
__m128i b9Max = _mm_max_epi16(a9, b9);
__m128i a10, b10;
unpack_epi16_ab(a9Min, b9Max, a10, b10);
__m128i a10Min = _mm_min_epi16(a10, b10);
__m128i b10Max = _mm_max_epi16(a10, b10);
unpack_epi16_ab(a10Min, b10Max, aOut, bOut);
}
This is verified using the standard 0/1 technique described in Knuth.
The compiled code uses only five registers, so avoids register spills.
I am still not sure if this was worth the effort. But it's done.
Twice as many signed shorts can be fit into the same space. And SSE2 has intrinsics for maximum and minimum for 8 signed short numbers at a time using _mm_min_epi16 and _mm_max_epi16.
While the bitonic sorting network for 16 values requires 10 min/max pairs rather than the 9 required in the network shown in Knuth, the shuffles are much easier for the plain vanilla bitonic sorting network.

A lot of shuffling has to happen to make this all work. The unpack operations will happen in pairs:
void unpack_epi16_ab(const __m128i &a, const __m128i &b, __m128i &aOut, __m128i &bOut)
{
__m128i aa = _mm_unpacklo_epi16(a, b);
__m128i bb = _mm_unpackhi_epi16(a, b);
aOut = aa;
bOut = bb;
}
void unpack_epi32_ab(const __m128i &a, const __m128i &b, __m128i &aOut, __m128i &bOut)
{
__m128i aa = _mm_unpacklo_epi32(a, b);
__m128i bb = _mm_unpackhi_epi32(a, b);
aOut = aa;
bOut = bb;
}
void unpack_epi64_ab(const __m128i &a, const __m128i &b, __m128i &aOut, __m128i &bOut)
{
__m128i aa = _mm_unpacklo_epi64(a, b);
__m128i bb = _mm_unpackhi_epi64(a, b);
aOut = aa;
bOut = bb;
}
Note that it is safe to call all of these with the same variables used as input and output.
void BitonicSortingNetwork_epi16_SSE2(const __m128i &a, const __m128i &b, __m128i &aOut, __m128i &bOut)
{
__m128i a1 = a;
__m128i b1 = b;
__m128i a1Min = _mm_min_epi16(a1, b1);
__m128i b1Max = _mm_max_epi16(a1, b1);
__m128i a2 = a1Min;
__m128i b2 = _mm_shufflelo_epi16(b1Max, _MM_SHUFFLE(2, 3, 0, 1));
b2 = _mm_shufflehi_epi16(b2, _MM_SHUFFLE(2, 3, 0, 1));
__m128i a2Min = _mm_min_epi16(a2, b2);
__m128i b2Max = _mm_max_epi16(a2, b2);
__m128i a3, b3;
unpack_epi16_ab(a2Min, b2Max, a3, b3);
unpack_epi16_ab(a3, b3, a3, b3);
unpack_epi16_ab(a3, b3, a3, b3);
__m128i a3Min = _mm_min_epi16(a3, b3);
__m128i b3Max = _mm_max_epi16(a3, b3);
__m128i a4, b4;
unpack_epi32_ab(a3Min, b3Max, a4, b4);
a4 = _mm_shufflelo_epi16(a4, _MM_SHUFFLE(0, 1, 2, 3));
b4 = _mm_shufflehi_epi16(b4, _MM_SHUFFLE(0, 1, 2, 3));
__m128i a4Min = _mm_min_epi16(a4, b4);
__m128i b4Max = _mm_max_epi16(a4, b4);
__m128i a5, b5;
unpack_epi16_ab(a4Min, b4Max, a5, b5);
unpack_epi64_ab(a5, b5, a5, b5);
a5 = _mm_shuffle_epi32(a5, _MM_SHUFFLE(2, 3, 0, 1));
__m128i a5Min = _mm_min_epi16(a5, b5);
__m128i b5Max = _mm_max_epi16(a5, b5);
__m128i a6, b6;
unpack_epi16_ab(a5Min, b5Max, a6, b6);
unpack_epi16_ab(a6, b6, a6, b6);
__m128i a6Min = _mm_min_epi16(a6, b6);
__m128i b6Max = _mm_max_epi16(a6, b6);
__m128i a7, b7;
b7 = _mm_shuffle_epi32(b6Max, _MM_SHUFFLE(1, 0, 3, 2));
b7 = _mm_shufflehi_epi16(b7, _MM_SHUFFLE(0, 1, 2, 3));
a7 = _mm_shufflelo_epi16(a6Min, _MM_SHUFFLE(0, 1, 2, 3));
__m128i a7Min = _mm_min_epi16(a7, b7);
__m128i b7Max = _mm_max_epi16(a7, b7);
__m128i a8, b8;
unpack_epi16_ab(a7Min, b7Max, b8, a8);
a8 = _mm_shuffle_epi32(a8, _MM_SHUFFLE(0, 1, 2, 3));
__m128i a8Min = _mm_min_epi16(a8, b8);
__m128i b8Max = _mm_max_epi16(a8, b8);
__m128i a9, b9;
unpack_epi16_ab(a8Min, b8Max, a9, b9);
__m128i a9Min = _mm_min_epi16(a9, b9);
__m128i b9Max = _mm_max_epi16(a9, b9);
__m128i a10, b10;
unpack_epi16_ab(a9Min, b9Max, a10, b10);
__m128i a10Min = _mm_min_epi16(a10, b10);
__m128i b10Max = _mm_max_epi16(a10, b10);
unpack_epi16_ab(a10Min, b10Max, aOut, bOut);
}
This is verified using the standard 0/1 technique described in Knuth.
The compiled code uses only five registers, so avoids register spills.
I am still not sure if this was worth the effort. But it's done.
Sunday, March 19, 2017
shaving a few shuffles from the float sorting network in SSE2
In an earlier post I commented that I felt that it should be possible to get rid of a couple shuffles in the presented network.

Below is a network implementation of the same bitonic network above. But this new implementation seems to have a handful fewer shuffles.
void BitonicSortingNetwork_FewerShuffles_SSE2(const __m128 &a, const __m128 &b, __m128 &aOut, __m128 &bOut)
{
__m128 a1 = a;
__m128 b1 = b;
__m128 a1Min = _mm_min_ps(a1, b1); // 1357
__m128 b1Max = _mm_max_ps(a1, b1); // 2468
__m128 a2 = a1Min; // 1357
__m128 b2 = _mm_shuffle_ps(b1Max, b1Max, _MM_SHUFFLE(2, 3, 0, 1)); // 4286
__m128 a2Min = _mm_min_ps(a2, b2); // 1256
__m128 b2Max = _mm_max_ps(a2, b2); // 4387
__m128 a3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(3, 1, 2, 0)); // 1537
__m128 b3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(2, 0, 3,1)); // 2648
__m128 a3Min = _mm_min_ps(a3, b3); // 1537
__m128 b3Max = _mm_max_ps(a3, b3); // 2648
__m128 a4 = a3Min; // 1537
__m128 b4 = _mm_shuffle_ps(b3Max, b3Max, _MM_SHUFFLE(0, 1, 2, 3)); // 8462
__m128 a4Min = _mm_min_ps(a4, b4); // 1432
__m128 b4Max = _mm_max_ps(a4, b4); // 8567
__m128 a5 = _mm_unpacklo_ps(a4Min, b4Max); // 1845
__m128 b5 = _mm_unpackhi_ps(a4Min, b4Max); // 3627
__m128 a5Min = _mm_min_ps(a5, b5); // 1625
__m128 b5Max = _mm_max_ps(a5, b5); // 3847
__m128 a6 = _mm_unpacklo_ps(a5Min, b5Max); // 1368
__m128 b6 = _mm_unpackhi_ps(a5Min, b5Max); // 2457
__m128 a6Min = _mm_min_ps(a6, b6); // 1357
__m128 b6Max = _mm_max_ps(a6, b6); // 2468
aOut = _mm_unpacklo_ps(a6Min, b6Max); // 1234
bOut = _mm_unpackhi_ps(a6Min, b6Max); // 5678
}
In particular it arranges to have only the unpacks before returning the results. By re-using an intermediate, two shuffles are eliminated between min/max. While this only shaves a cycle or two from the runtime, it is more aesthetically pleasing.
The compiled assembly code looks good.
__m128 a1 = a;
00007FF751C51070 movups xmm3,xmmword ptr [rcx]
__m128 b1 = b;
__m128 a1Min = _mm_min_ps(a1, b1); // 1357
__m128 b1Max = _mm_max_ps(a1, b1); // 2468
00007FF751C51073 movaps xmm1,xmm3
00007FF751C51076 maxps xmm1,xmmword ptr [rdx]
00007FF751C51079 minps xmm3,xmmword ptr [rdx]
__m128 a2 = a1Min; // 1357
__m128 b2 = _mm_shuffle_ps(b1Max, b1Max, _MM_SHUFFLE(2, 3, 0, 1)); // 4286
00007FF751C5107C shufps xmm1,xmm1,0B1h
__m128 a2Min = _mm_min_ps(a2, b2); // 1256
00007FF751C51080 movaps xmm2,xmm3
00007FF751C51083 minps xmm2,xmm1
__m128 b2Max = _mm_max_ps(a2, b2); // 4387
00007FF751C51086 maxps xmm3,xmm1
__m128 a3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(3, 1, 2, 0)); // 1537
00007FF751C51089 movaps xmm4,xmm2
__m128 b3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(2, 0, 3, 1)); // 2648
00007FF751C5108C shufps xmm2,xmm3,8Dh
__m128 b3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(2, 0, 3, 1)); // 2648
00007FF751C51090 shufps xmm4,xmm3,0D8h
__m128 a3Min = _mm_min_ps(a3, b3); // 1537
__m128 b3Max = _mm_max_ps(a3, b3); // 2648
00007FF751C51094 movaps xmm0,xmm4
00007FF751C51097 maxps xmm0,xmm2
00007FF751C5109A minps xmm4,xmm2
__m128 a4 = a3Min; // 1537
__m128 b4 = _mm_shuffle_ps(b3Max, b3Max, _MM_SHUFFLE(0, 1, 2, 3)); // 8462
00007FF751C5109D shufps xmm0,xmm0,1Bh
__m128 a4Min = _mm_min_ps(a4, b4); // 1432
00007FF751C510A1 movaps xmm1,xmm4
00007FF751C510A4 minps xmm1,xmm0
__m128 b4Max = _mm_max_ps(a4, b4); // 8567
00007FF751C510A7 maxps xmm4,xmm0
__m128 a5 = _mm_unpacklo_ps(a4Min, b4Max); // 1845
00007FF751C510AA movaps xmm0,xmm1
__m128 b5 = _mm_unpackhi_ps(a4Min, b4Max); // 3627
00007FF751C510AD unpckhps xmm1,xmm4
00007FF751C510B0 unpcklps xmm0,xmm4
__m128 a5Min = _mm_min_ps(a5, b5); // 1625
00007FF751C510B3 movaps xmm2,xmm0
__m128 b5Max = _mm_max_ps(a5, b5); // 3847
00007FF751C510B6 maxps xmm0,xmm1
00007FF751C510B9 minps xmm2,xmm1
__m128 a6 = _mm_unpacklo_ps(a5Min, b5Max); // 1368
00007FF751C510BC movaps xmm3,xmm2
__m128 b6 = _mm_unpackhi_ps(a5Min, b5Max); // 2457
00007FF751C510BF unpckhps xmm2,xmm0
00007FF751C510C2 unpcklps xmm3,xmm0
__m128 a6Min = _mm_min_ps(a6, b6); // 1357
00007FF751C510C5 movaps xmm1,xmm3
00007FF751C510C8 minps xmm1,xmm2
__m128 b6Max = _mm_max_ps(a6, b6); // 2468
00007FF751C510CB maxps xmm3,xmm2
aOut = _mm_unpacklo_ps(a6Min, b6Max); // 1234
00007FF751C510CE movaps xmm0,xmm1
00007FF751C510D1 unpcklps xmm0,xmm3
bOut = _mm_unpackhi_ps(a6Min, b6Max); // 5678
00007FF751C510D4 unpckhps xmm1,xmm3
00007FF751C510D7 movups xmmword ptr [r8],xmm0
00007FF751C510DB movups xmmword ptr [r9],xmm1
}
00007FF751C510DF ret
Update: I see that the final three stages are the same as what is described in a paper that I read but hadn't remembered. I find a different paper in a quick search. I think that the first three stages are better than what are described in that paper. But incorporated into a much larger mergesort gives a different set of problems. Also, the papers don't give source code...

Below is a network implementation of the same bitonic network above. But this new implementation seems to have a handful fewer shuffles.
void BitonicSortingNetwork_FewerShuffles_SSE2(const __m128 &a, const __m128 &b, __m128 &aOut, __m128 &bOut)
{
__m128 a1 = a;
__m128 b1 = b;
__m128 a1Min = _mm_min_ps(a1, b1); // 1357
__m128 b1Max = _mm_max_ps(a1, b1); // 2468
__m128 a2 = a1Min; // 1357
__m128 b2 = _mm_shuffle_ps(b1Max, b1Max, _MM_SHUFFLE(2, 3, 0, 1)); // 4286
__m128 a2Min = _mm_min_ps(a2, b2); // 1256
__m128 b2Max = _mm_max_ps(a2, b2); // 4387
__m128 a3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(3, 1, 2, 0)); // 1537
__m128 b3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(2, 0, 3,1)); // 2648
__m128 a3Min = _mm_min_ps(a3, b3); // 1537
__m128 b3Max = _mm_max_ps(a3, b3); // 2648
__m128 a4 = a3Min; // 1537
__m128 b4 = _mm_shuffle_ps(b3Max, b3Max, _MM_SHUFFLE(0, 1, 2, 3)); // 8462
__m128 a4Min = _mm_min_ps(a4, b4); // 1432
__m128 b4Max = _mm_max_ps(a4, b4); // 8567
__m128 a5 = _mm_unpacklo_ps(a4Min, b4Max); // 1845
__m128 b5 = _mm_unpackhi_ps(a4Min, b4Max); // 3627
__m128 a5Min = _mm_min_ps(a5, b5); // 1625
__m128 b5Max = _mm_max_ps(a5, b5); // 3847
__m128 a6 = _mm_unpacklo_ps(a5Min, b5Max); // 1368
__m128 b6 = _mm_unpackhi_ps(a5Min, b5Max); // 2457
__m128 a6Min = _mm_min_ps(a6, b6); // 1357
__m128 b6Max = _mm_max_ps(a6, b6); // 2468
aOut = _mm_unpacklo_ps(a6Min, b6Max); // 1234
bOut = _mm_unpackhi_ps(a6Min, b6Max); // 5678
}
In particular it arranges to have only the unpacks before returning the results. By re-using an intermediate, two shuffles are eliminated between min/max. While this only shaves a cycle or two from the runtime, it is more aesthetically pleasing.
The compiled assembly code looks good.
__m128 a1 = a;
00007FF751C51070 movups xmm3,xmmword ptr [rcx]
__m128 b1 = b;
__m128 a1Min = _mm_min_ps(a1, b1); // 1357
__m128 b1Max = _mm_max_ps(a1, b1); // 2468
00007FF751C51073 movaps xmm1,xmm3
00007FF751C51076 maxps xmm1,xmmword ptr [rdx]
00007FF751C51079 minps xmm3,xmmword ptr [rdx]
__m128 a2 = a1Min; // 1357
__m128 b2 = _mm_shuffle_ps(b1Max, b1Max, _MM_SHUFFLE(2, 3, 0, 1)); // 4286
00007FF751C5107C shufps xmm1,xmm1,0B1h
__m128 a2Min = _mm_min_ps(a2, b2); // 1256
00007FF751C51080 movaps xmm2,xmm3
00007FF751C51083 minps xmm2,xmm1
__m128 b2Max = _mm_max_ps(a2, b2); // 4387
00007FF751C51086 maxps xmm3,xmm1
__m128 a3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(3, 1, 2, 0)); // 1537
00007FF751C51089 movaps xmm4,xmm2
__m128 b3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(2, 0, 3, 1)); // 2648
00007FF751C5108C shufps xmm2,xmm3,8Dh
__m128 b3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(2, 0, 3, 1)); // 2648
00007FF751C51090 shufps xmm4,xmm3,0D8h
__m128 a3Min = _mm_min_ps(a3, b3); // 1537
__m128 b3Max = _mm_max_ps(a3, b3); // 2648
00007FF751C51094 movaps xmm0,xmm4
00007FF751C51097 maxps xmm0,xmm2
00007FF751C5109A minps xmm4,xmm2
__m128 a4 = a3Min; // 1537
__m128 b4 = _mm_shuffle_ps(b3Max, b3Max, _MM_SHUFFLE(0, 1, 2, 3)); // 8462
00007FF751C5109D shufps xmm0,xmm0,1Bh
__m128 a4Min = _mm_min_ps(a4, b4); // 1432
00007FF751C510A1 movaps xmm1,xmm4
00007FF751C510A4 minps xmm1,xmm0
__m128 b4Max = _mm_max_ps(a4, b4); // 8567
00007FF751C510A7 maxps xmm4,xmm0
__m128 a5 = _mm_unpacklo_ps(a4Min, b4Max); // 1845
00007FF751C510AA movaps xmm0,xmm1
__m128 b5 = _mm_unpackhi_ps(a4Min, b4Max); // 3627
00007FF751C510AD unpckhps xmm1,xmm4
00007FF751C510B0 unpcklps xmm0,xmm4
__m128 a5Min = _mm_min_ps(a5, b5); // 1625
00007FF751C510B3 movaps xmm2,xmm0
__m128 b5Max = _mm_max_ps(a5, b5); // 3847
00007FF751C510B6 maxps xmm0,xmm1
00007FF751C510B9 minps xmm2,xmm1
__m128 a6 = _mm_unpacklo_ps(a5Min, b5Max); // 1368
00007FF751C510BC movaps xmm3,xmm2
__m128 b6 = _mm_unpackhi_ps(a5Min, b5Max); // 2457
00007FF751C510BF unpckhps xmm2,xmm0
00007FF751C510C2 unpcklps xmm3,xmm0
__m128 a6Min = _mm_min_ps(a6, b6); // 1357
00007FF751C510C5 movaps xmm1,xmm3
00007FF751C510C8 minps xmm1,xmm2
__m128 b6Max = _mm_max_ps(a6, b6); // 2468
00007FF751C510CB maxps xmm3,xmm2
aOut = _mm_unpacklo_ps(a6Min, b6Max); // 1234
00007FF751C510CE movaps xmm0,xmm1
00007FF751C510D1 unpcklps xmm0,xmm3
bOut = _mm_unpackhi_ps(a6Min, b6Max); // 5678
00007FF751C510D4 unpckhps xmm1,xmm3
00007FF751C510D7 movups xmmword ptr [r8],xmm0
00007FF751C510DB movups xmmword ptr [r9],xmm1
}
00007FF751C510DF ret
Wednesday, March 15, 2017
A bitonic sorting network for 8 floats in SSE2
The previous sorting network did perform the sort in the ideal number of min/max operations. But there was a lot of shuffling. But this did strict ordering of the input wires. If instead we allow the input wires to be reordered to make the shuffles more efficient, we can do a little better.
The below is a bitonic sorting network performed in this manner. We shuffle to get the correct comparisons without regard to where in the registers the conceptual input wires are located. This verifies as correct with the standard 0/1 method.
The below network is done with floats, since all of the necessary intrisics are available in SSE2.
void BitonicSortingNetwork_SSE2(const __m128 &a, const __m128 &b, __m128 &aOut, __m128 &bOut)
{
__m128 a1 = _mm_shuffle_ps(a, b, _MM_SHUFFLE(2, 0, 2, 0)); // 1357
__m128 b1 = _mm_shuffle_ps(a, b, _MM_SHUFFLE(3, 1, 3, 1)); // 2468
__m128 a1Min = _mm_min_ps(a1, b1);
__m128 b1Max = _mm_max_ps(a1, b1);
__m128 a2 = _mm_shuffle_ps(a1Min, b1Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1526
__m128 b2 = _mm_shuffle_ps(b1Max, a1Min, _MM_SHUFFLE(3, 1, 3, 1)); // 4837
__m128 a2Min = _mm_min_ps(a2, b2);
__m128 b2Max = _mm_max_ps(a2, b2);
__m128 a3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(3, 2, 1, 0)); // 1537
__m128 b3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(1, 0, 3, 2)); // 2648
__m128 a3Min = _mm_min_ps(a3, b3);
__m128 b3Max = _mm_max_ps(a3, b3);
__m128 a4 = _mm_shuffle_ps(a3Min, b3Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1324
__m128 b4 = _mm_shuffle_ps(b3Max, a3Min, _MM_SHUFFLE(1, 3, 1, 3)); // 8675
__m128 a4Min = _mm_min_ps(a4, b4);
__m128 b4Max = _mm_max_ps(a4, b4);
__m128 a5 = _mm_shuffle_ps(a4Min, b4Max, _MM_SHUFFLE(1, 3, 2, 0)); // 1256
__m128 b5 = _mm_shuffle_ps(a4Min, b4Max, _MM_SHUFFLE(0, 2, 3, 1)); // 3478
__m128 a5Min = _mm_min_ps(a5, b5);
__m128 b5Max = _mm_max_ps(a5, b5);
__m128 a6 = _mm_shuffle_ps(a5Min, b5Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1537
__m128 b6 = _mm_shuffle_ps(a5Min, b5Max, _MM_SHUFFLE(3, 1, 3, 1)); // 2648
__m128 a6Min = _mm_min_ps(a6, b6);
__m128 b6Max = _mm_max_ps(a6, b6);
__m128 a7 = _mm_shuffle_ps(a6Min, b6Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1324
__m128 b7 = _mm_shuffle_ps(a6Min, b6Max, _MM_SHUFFLE(3, 1, 3, 1)); // 5768
aOut = _mm_shuffle_ps(a7, a7, _MM_SHUFFLE(3, 1, 2, 0)); // 1234
bOut = _mm_shuffle_ps(b7, b7, _MM_SHUFFLE(3, 1, 2, 0)); // 5678
}
The comments reflect where in the registers the conceptual input wires are located.
Since this is in fact a sorting network, the order of the inputs isn't important, and the first pair of shuffles is unnecessary. I've tried to figure out a way of getting rid of the final double shuffle, but I haven't been able to get rid of it.
Here's the assembly of the compilation without the initial shuffles:
__m128 a1 = a;
000000013F1B1140 movaps xmm2,xmmword ptr [rcx]
__m128 b1 = b;
__m128 a1Min = _mm_min_ps(a1, b1);
000000013F1B1143 movaps xmm1,xmm2
__m128 b1Max = _mm_max_ps(a1, b1);
000000013F1B1146 maxps xmm2,xmmword ptr [rdx]
000000013F1B1149 minps xmm1,xmmword ptr [rdx]
__m128 a2 = _mm_shuffle_ps(a1Min, b1Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1526
000000013F1B114C movaps xmm0,xmm1
000000013F1B114F shufps xmm0,xmm2,88h
__m128 b2 = _mm_shuffle_ps(b1Max, a1Min, _MM_SHUFFLE(3, 1, 3, 1)); // 4837
000000013F1B1153 shufps xmm2,xmm1,0DDh
__m128 a2Min = _mm_min_ps(a2, b2);
000000013F1B1157 movaps xmm1,xmm0
__m128 b2Max = _mm_max_ps(a2, b2);
000000013F1B115A maxps xmm0,xmm2
000000013F1B115D minps xmm1,xmm2
__m128 a3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(3, 2, 1, 0)); // 1537
000000013F1B1160 movaps xmm2,xmm1
__m128 b3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(1, 0, 3, 2)); // 2648
000000013F1B1163 shufps xmm1,xmm0,4Eh
000000013F1B1167 shufps xmm2,xmm0,0E4h
__m128 a3Min = _mm_min_ps(a3, b3);
000000013F1B116B movaps xmm0,xmm2
__m128 b3Max = _mm_max_ps(a3, b3);
000000013F1B116E maxps xmm2,xmm1
000000013F1B1171 minps xmm0,xmm1
__m128 a4 = _mm_shuffle_ps(a3Min, b3Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1324
000000013F1B1174 movaps xmm1,xmm0
000000013F1B1177 shufps xmm1,xmm2,88h
__m128 b4 = _mm_shuffle_ps(b3Max, a3Min, _MM_SHUFFLE(1, 3, 1, 3)); // 8675
000000013F1B117B shufps xmm2,xmm0,77h
__m128 a4Min = _mm_min_ps(a4, b4);
000000013F1B117F movaps xmm0,xmm1
000000013F1B1182 minps xmm0,xmm2
__m128 b4Max = _mm_max_ps(a4, b4);
000000013F1B1185 maxps xmm1,xmm2
__m128 a5 = _mm_shuffle_ps(a4Min, b4Max, _MM_SHUFFLE(1, 3, 2, 0)); // 1256
000000013F1B1188 movaps xmm2,xmm0
000000013F1B118B shufps xmm2,xmm1,78h
__m128 b5 = _mm_shuffle_ps(a4Min, b4Max, _MM_SHUFFLE(0, 2, 3, 1)); // 3478
000000013F1B118F shufps xmm0,xmm1,2Dh
__m128 a5Min = _mm_min_ps(a5, b5);
000000013F1B1193 movaps xmm1,xmm2
__m128 b5Max = _mm_max_ps(a5, b5);
000000013F1B1196 maxps xmm2,xmm0
000000013F1B1199 minps xmm1,xmm0
__m128 a6 = _mm_shuffle_ps(a5Min, b5Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1537
000000013F1B119C movaps xmm3,xmm1
__m128 b6 = _mm_shuffle_ps(a5Min, b5Max, _MM_SHUFFLE(3, 1, 3, 1)); // 2648
000000013F1B119F shufps xmm1,xmm2,0DDh
000000013F1B11A3 shufps xmm3,xmm2,88h
__m128 a6Min = _mm_min_ps(a6, b6);
000000013F1B11A7 movaps xmm2,xmm3
000000013F1B11AA minps xmm2,xmm1
__m128 b6Max = _mm_max_ps(a6, b6);
000000013F1B11AD maxps xmm3,xmm1
__m128 a7 = _mm_shuffle_ps(a6Min, b6Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1324
000000013F1B11B0 movaps xmm0,xmm2
000000013F1B11B3 shufps xmm0,xmm3,88h
__m128 b7 = _mm_shuffle_ps(a6Min, b6Max, _MM_SHUFFLE(3, 1, 3, 1)); // 5768
000000013F1B11B7 shufps xmm2,xmm3,0DDh
aOut = _mm_shuffle_ps(a7, a7, _MM_SHUFFLE(3, 1, 2, 0)); // 1234
000000013F1B11BB shufps xmm0,xmm0,0D8h
bOut = _mm_shuffle_ps(b7, b7, _MM_SHUFFLE(3, 1, 2, 0)); // 5678
000000013F1B11BF shufps xmm2,xmm2,0D8h
000000013F1B11C3 movaps xmmword ptr [r8],xmm0
000000013F1B11C7 movaps xmmword ptr [r9],xmm2
}
000000013F1B11CB ret
This fits snugly into 4 registers. It looks pretty good.
The below is a bitonic sorting network performed in this manner. We shuffle to get the correct comparisons without regard to where in the registers the conceptual input wires are located. This verifies as correct with the standard 0/1 method.
The below network is done with floats, since all of the necessary intrisics are available in SSE2.
void BitonicSortingNetwork_SSE2(const __m128 &a, const __m128 &b, __m128 &aOut, __m128 &bOut)
{
__m128 a1 = _mm_shuffle_ps(a, b, _MM_SHUFFLE(2, 0, 2, 0)); // 1357
__m128 b1 = _mm_shuffle_ps(a, b, _MM_SHUFFLE(3, 1, 3, 1)); // 2468
__m128 a1Min = _mm_min_ps(a1, b1);
__m128 b1Max = _mm_max_ps(a1, b1);
__m128 a2 = _mm_shuffle_ps(a1Min, b1Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1526
__m128 b2 = _mm_shuffle_ps(b1Max, a1Min, _MM_SHUFFLE(3, 1, 3, 1)); // 4837
__m128 a2Min = _mm_min_ps(a2, b2);
__m128 b2Max = _mm_max_ps(a2, b2);
__m128 a3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(3, 2, 1, 0)); // 1537
__m128 b3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(1, 0, 3, 2)); // 2648
__m128 a3Min = _mm_min_ps(a3, b3);
__m128 b3Max = _mm_max_ps(a3, b3);
__m128 a4 = _mm_shuffle_ps(a3Min, b3Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1324
__m128 b4 = _mm_shuffle_ps(b3Max, a3Min, _MM_SHUFFLE(1, 3, 1, 3)); // 8675
__m128 a4Min = _mm_min_ps(a4, b4);
__m128 b4Max = _mm_max_ps(a4, b4);
__m128 a5 = _mm_shuffle_ps(a4Min, b4Max, _MM_SHUFFLE(1, 3, 2, 0)); // 1256
__m128 b5 = _mm_shuffle_ps(a4Min, b4Max, _MM_SHUFFLE(0, 2, 3, 1)); // 3478
__m128 a5Min = _mm_min_ps(a5, b5);
__m128 b5Max = _mm_max_ps(a5, b5);
__m128 a6 = _mm_shuffle_ps(a5Min, b5Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1537
__m128 b6 = _mm_shuffle_ps(a5Min, b5Max, _MM_SHUFFLE(3, 1, 3, 1)); // 2648
__m128 a6Min = _mm_min_ps(a6, b6);
__m128 b6Max = _mm_max_ps(a6, b6);
__m128 a7 = _mm_shuffle_ps(a6Min, b6Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1324
__m128 b7 = _mm_shuffle_ps(a6Min, b6Max, _MM_SHUFFLE(3, 1, 3, 1)); // 5768
aOut = _mm_shuffle_ps(a7, a7, _MM_SHUFFLE(3, 1, 2, 0)); // 1234
bOut = _mm_shuffle_ps(b7, b7, _MM_SHUFFLE(3, 1, 2, 0)); // 5678
}
The comments reflect where in the registers the conceptual input wires are located.
Since this is in fact a sorting network, the order of the inputs isn't important, and the first pair of shuffles is unnecessary. I've tried to figure out a way of getting rid of the final double shuffle, but I haven't been able to get rid of it.
Here's the assembly of the compilation without the initial shuffles:
__m128 a1 = a;
000000013F1B1140 movaps xmm2,xmmword ptr [rcx]
__m128 b1 = b;
__m128 a1Min = _mm_min_ps(a1, b1);
000000013F1B1143 movaps xmm1,xmm2
__m128 b1Max = _mm_max_ps(a1, b1);
000000013F1B1146 maxps xmm2,xmmword ptr [rdx]
000000013F1B1149 minps xmm1,xmmword ptr [rdx]
__m128 a2 = _mm_shuffle_ps(a1Min, b1Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1526
000000013F1B114C movaps xmm0,xmm1
000000013F1B114F shufps xmm0,xmm2,88h
__m128 b2 = _mm_shuffle_ps(b1Max, a1Min, _MM_SHUFFLE(3, 1, 3, 1)); // 4837
000000013F1B1153 shufps xmm2,xmm1,0DDh
__m128 a2Min = _mm_min_ps(a2, b2);
000000013F1B1157 movaps xmm1,xmm0
__m128 b2Max = _mm_max_ps(a2, b2);
000000013F1B115A maxps xmm0,xmm2
000000013F1B115D minps xmm1,xmm2
__m128 a3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(3, 2, 1, 0)); // 1537
000000013F1B1160 movaps xmm2,xmm1
__m128 b3 = _mm_shuffle_ps(a2Min, b2Max, _MM_SHUFFLE(1, 0, 3, 2)); // 2648
000000013F1B1163 shufps xmm1,xmm0,4Eh
000000013F1B1167 shufps xmm2,xmm0,0E4h
__m128 a3Min = _mm_min_ps(a3, b3);
000000013F1B116B movaps xmm0,xmm2
__m128 b3Max = _mm_max_ps(a3, b3);
000000013F1B116E maxps xmm2,xmm1
000000013F1B1171 minps xmm0,xmm1
__m128 a4 = _mm_shuffle_ps(a3Min, b3Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1324
000000013F1B1174 movaps xmm1,xmm0
000000013F1B1177 shufps xmm1,xmm2,88h
__m128 b4 = _mm_shuffle_ps(b3Max, a3Min, _MM_SHUFFLE(1, 3, 1, 3)); // 8675
000000013F1B117B shufps xmm2,xmm0,77h
__m128 a4Min = _mm_min_ps(a4, b4);
000000013F1B117F movaps xmm0,xmm1
000000013F1B1182 minps xmm0,xmm2
__m128 b4Max = _mm_max_ps(a4, b4);
000000013F1B1185 maxps xmm1,xmm2
__m128 a5 = _mm_shuffle_ps(a4Min, b4Max, _MM_SHUFFLE(1, 3, 2, 0)); // 1256
000000013F1B1188 movaps xmm2,xmm0
000000013F1B118B shufps xmm2,xmm1,78h
__m128 b5 = _mm_shuffle_ps(a4Min, b4Max, _MM_SHUFFLE(0, 2, 3, 1)); // 3478
000000013F1B118F shufps xmm0,xmm1,2Dh
__m128 a5Min = _mm_min_ps(a5, b5);
000000013F1B1193 movaps xmm1,xmm2
__m128 b5Max = _mm_max_ps(a5, b5);
000000013F1B1196 maxps xmm2,xmm0
000000013F1B1199 minps xmm1,xmm0
__m128 a6 = _mm_shuffle_ps(a5Min, b5Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1537
000000013F1B119C movaps xmm3,xmm1
__m128 b6 = _mm_shuffle_ps(a5Min, b5Max, _MM_SHUFFLE(3, 1, 3, 1)); // 2648
000000013F1B119F shufps xmm1,xmm2,0DDh
000000013F1B11A3 shufps xmm3,xmm2,88h
__m128 a6Min = _mm_min_ps(a6, b6);
000000013F1B11A7 movaps xmm2,xmm3
000000013F1B11AA minps xmm2,xmm1
__m128 b6Max = _mm_max_ps(a6, b6);
000000013F1B11AD maxps xmm3,xmm1
__m128 a7 = _mm_shuffle_ps(a6Min, b6Max, _MM_SHUFFLE(2, 0, 2, 0)); // 1324
000000013F1B11B0 movaps xmm0,xmm2
000000013F1B11B3 shufps xmm0,xmm3,88h
__m128 b7 = _mm_shuffle_ps(a6Min, b6Max, _MM_SHUFFLE(3, 1, 3, 1)); // 5768
000000013F1B11B7 shufps xmm2,xmm3,0DDh
aOut = _mm_shuffle_ps(a7, a7, _MM_SHUFFLE(3, 1, 2, 0)); // 1234
000000013F1B11BB shufps xmm0,xmm0,0D8h
bOut = _mm_shuffle_ps(b7, b7, _MM_SHUFFLE(3, 1, 2, 0)); // 5678
000000013F1B11BF shufps xmm2,xmm2,0D8h
000000013F1B11C3 movaps xmmword ptr [r8],xmm0
000000013F1B11C7 movaps xmmword ptr [r9],xmm2
}
000000013F1B11CB ret
This fits snugly into 4 registers. It looks pretty good.
Wednesday, March 1, 2017
Perfect shuffles of 16bit numbers in two registers
In a single 128bit register, one can store eight 16bit numbers. For a pair of these 128bit registers, the instruction pair _mm_unpacklo_epi16 and _mm_unpackhi_epi16, called with the same two registers as arguments, will conceptually perform a perfect shuffle of the 16-bit numbers in the registers.
void printm_epu16(const __m128i &mx)
{
for (int iA = 0; iA < ARRAYSIZE(mx.m128i_u16); iA++)
{
printf("%x", mx.m128i_u16[iA]);
}
}
int main()
{
__m128i a = _mm_setr_epi16(0, 1, 2, 3, 4, 5, 6, 7);
__m128i b = _mm_setr_epi16(8, 9, 10, 11, 12, 13, 14, 15);
printm_epu16(a);
printm_epu16(b);
printf("\n");
for (int i = 0; i < 4; i++)
{
__m128i aa = _mm_unpacklo_epi16(a, b);
__m128i bb = _mm_unpackhi_epi16(a, b);
a = aa;
b = bb;
printm_epu16(a);
printm_epu16(b);
printf("\n");
}
}
will yield the output:
0123456789abcdef
08192a3b4c5d6e7f
048c159d26ae37bf
02468ace13579bdf
0123456789abcdef
We see that this cycle repeats after four iterations.
void printm_epu16(const __m128i &mx)
{
for (int iA = 0; iA < ARRAYSIZE(mx.m128i_u16); iA++)
{
printf("%x", mx.m128i_u16[iA]);
}
}
int main()
{
__m128i a = _mm_setr_epi16(0, 1, 2, 3, 4, 5, 6, 7);
__m128i b = _mm_setr_epi16(8, 9, 10, 11, 12, 13, 14, 15);
printm_epu16(a);
printm_epu16(b);
printf("\n");
for (int i = 0; i < 4; i++)
{
__m128i aa = _mm_unpacklo_epi16(a, b);
__m128i bb = _mm_unpackhi_epi16(a, b);
a = aa;
b = bb;
printm_epu16(a);
printm_epu16(b);
printf("\n");
}
}
will yield the output:
0123456789abcdef
08192a3b4c5d6e7f
048c159d26ae37bf
02468ace13579bdf
0123456789abcdef
We see that this cycle repeats after four iterations.
Subscribe to:
Comments (Atom)